Extracting information from a typical image file used to be quite tedious.
Back then, you will probably be using either Computer Vision model like YOLO or OCR software to first extract the text before you can do anything else.
Things started to change with the introduction of Vision Large Language model (VLLM), where one can attached the image and start asking the LLM with your query. The caveat was that you will need to know some coding to do it and the result then is somehow not idea, unless you go down the fine-tune route.
With the competition going between the big boys in the silicon valley on who will come out with the better model, we stand to benefit from it.
Even with this, one may still argue that the better models are still the ones that we either have to pay a subscription fee or API calls. While on the end, we are always watchful on exposing our data.
Then came Meta, who introduced its multimodal – llama 3.2 https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/.
With reference to Meta chart below, the performance of its small model – llama 3.2 11B was not far from a well known model, GPT-4o-mini with NO subscription free.

Finally in this month – Nov 24, the more exciting news was released by Ollama,
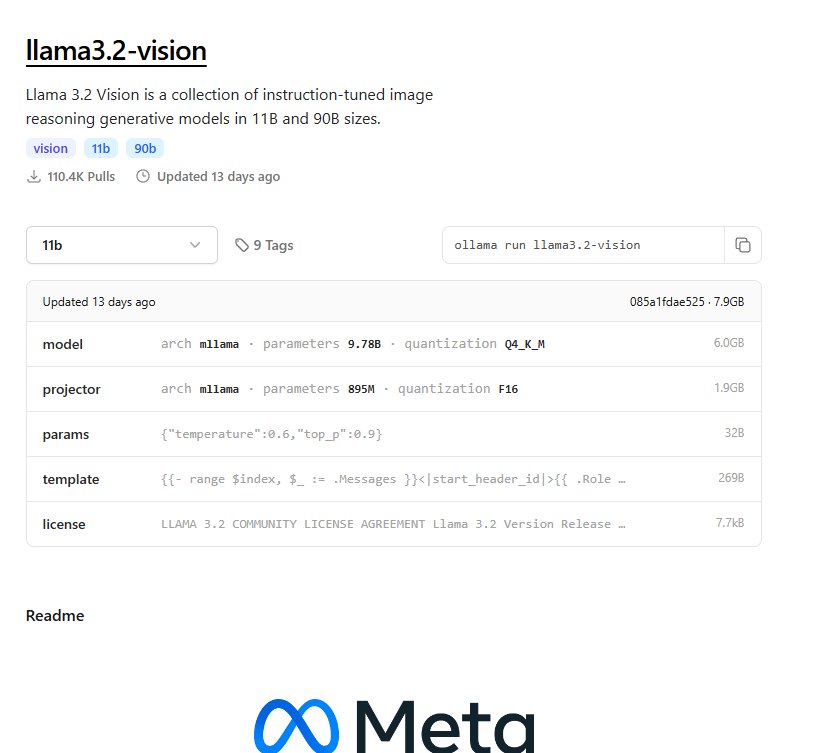
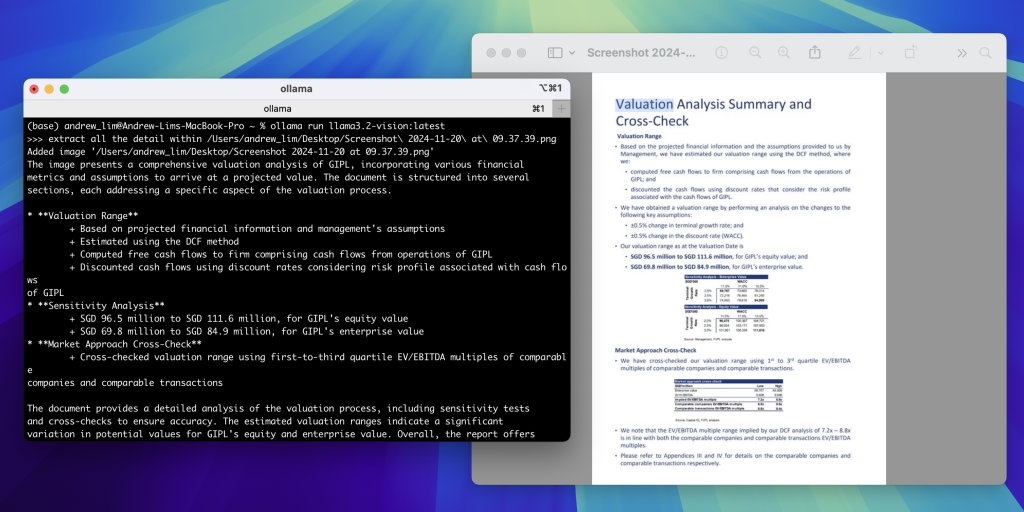
You can own the quantised version of the llama3.2-vision within your own machine.
What does it mean for layman (I am referring to non-tech peers), we can now run the “chat with my image” function within our PC/mac without connecting to the web.
https://ollama.com/blog/llama3.2-vision
This no doubt keep all your ‘secrets’ within your machine with zero cost. Hurray !!!